
Rate Limiting at the Edge with HAProxy: Part 2
In the previous blog, I showed you different parts of the configuration needed to implement a rate limiter using HAProxy. Now I will show you how we went about implementing it in production and some of the learnings along the way. I would like to note that at OneLogin, we have multiple layers in our stack that handle rate limiting, not just HAProxy. Utilizing HAProxy gave us a nice way to implement rate limiters at our edge.
The Problem
First, let’s describe some of the issues we were trying to solve:
-
Burst protection (DoS/Thundering Herd)
- Autoscaling of our larger services meant horizontal scaling isn’t quick enough for this problem.
- The multi-tenant nature of our platform can cause noisy-neighbor syndrome (this often isn’t intentionally done by clients).
-
Upstream resource protection
- Prevent request threads from being starved.
- Prevent databases and queues from getting overloaded.
-
Security
- Protection against brute-forcing login routes.
- Give our Security team extra levers for malicious clients.
The requirements we had were fourfold:
- End-user routes are first-class citizens
- Ability to customize easily and quickly without having to schedule a release
- Limit by source IP and route combined
- Ability to have different thresholds per route
Not covered in the initial iteration:
- Distributed counters (this is when you share counter data among multiple processes or nodes)
- Different limits per IP per route
- Exclusion lists
First Rollout
Our first rollout worked, kind of. The first iteration looked something like this:
frontend https-in
[...]
http-request track-sc1 base32+src table login_slo_routes if { path,map_reg(/etc/haproxy/login_slo_routes.map) -m found }
http-request set-var(txn.request_rate) base32+src,table_http_req_rate(login_slo_routes)
http-request set-var(txn.rate_limit) path,map_reg(/etc/haproxy/login_slo_routes.map)
http-request deny deny_status 429 if { var(txn.rate_limit),sub(txn.request_rate) lt 0 }
[...]
backend login_slo_routes
stick-table type binary len 8 size 10m expire 60s store http_req_rate(60s)
We noticed more 429s than we initially expected coming from an IP. Not a big deal as the rate limiter must be working as expected. But at a closer look, their success ratio was way lower than expected, almost zero.
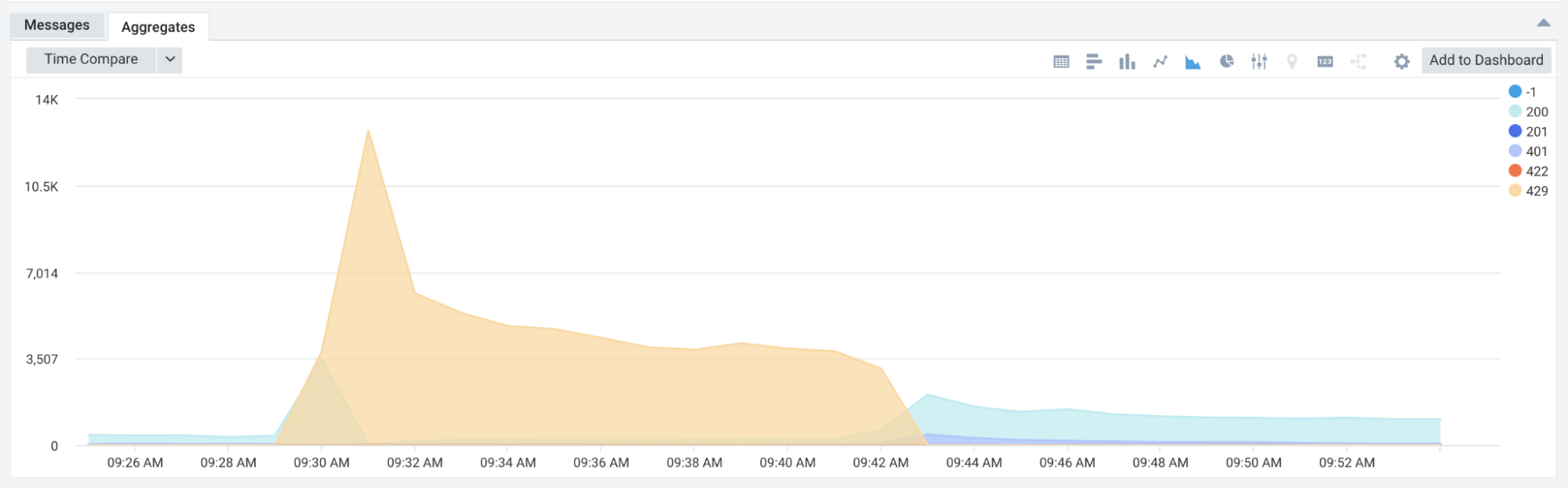
A client had reached their rate limit in a single minute, and their retry mechanism began retrying rapidly. As a result, most of their requests were getting rate-limited. When reviewing logs, the cause was the way we implemented the counter to include requests over the limit. Essentially we were using the leaky bucket algorithm but still counting the overage of requests. Until the client dropped their overall request rate back below the limit, we continued to return a 429 for every request.
To fix this, we needed to move the incrementor (track-sc1) to a position that only would trigger on accepted requests, so we guarantee that there is always throughput of valid requests. The resulting configuration looked like this:
frontend https-in
[...]
http-request set-var(txn.request_rate) base32+src,table_http_req_rate(login_slo_routes)
http-request set-var(txn.rate_limit) path,map_reg(/etc/haproxy/login_slo_routes.map)
http-request deny deny_status 429 if { var(txn.rate_limit),sub(txn.request_rate) lt 0 }
http-request track-sc1 base32+src table login_slo_routes if { path,map_reg(/etc/haproxy/login_slo_routes.map) -m found }
[...]
backend login_slo_routes
stick-table type binary len 8 size 10m expire 60s store http_req_rate(60s)
Subsequent Rollouts
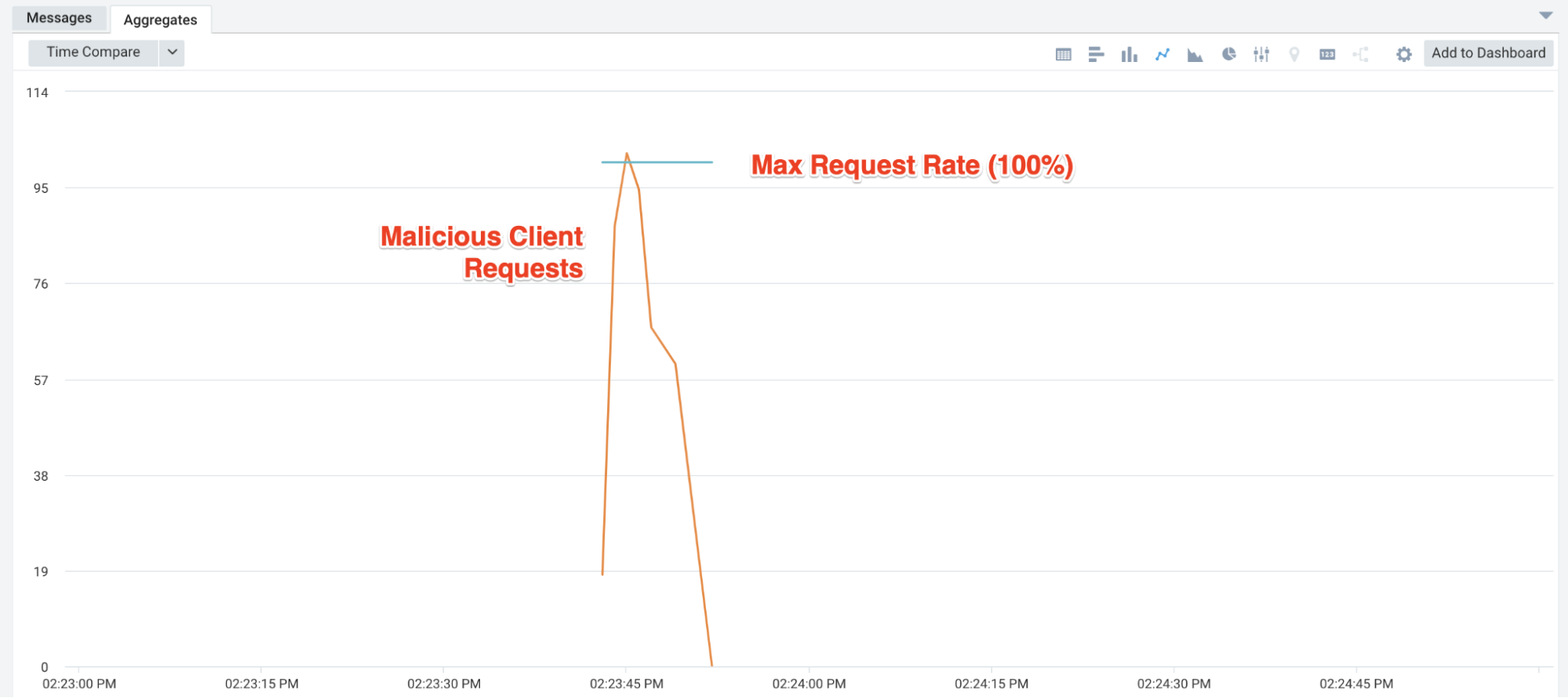
Once solved, we still faced another issue: we were seeing that our rate limiter wasn’t catching burst traffic fast enough. Some of our core services that autoscale take time because of their size and bootstrapping process - while we are always working on bringing that time down as low as possible it won’t get to the point that they can cover such unexpected burst traffic. So even though autoscaling was working, it wasn’t fast enough to handle burst situations. We wanted our rate limiter to catch misconfigured clients from causing issues, but our rolling 60-second windows were way too long.
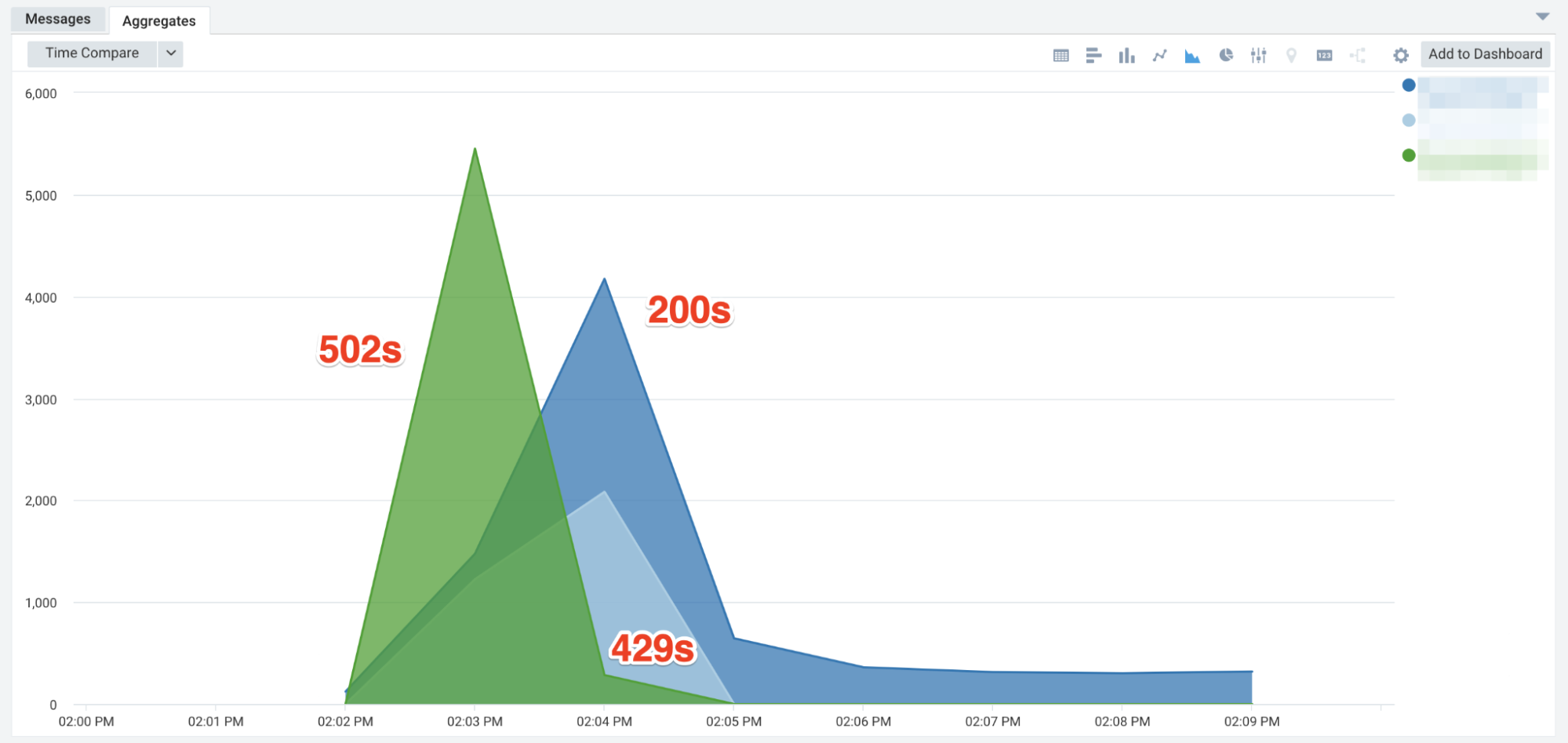
We tried a few iterations, 30-seconds & 15-seconds, but continued to have some clients hammer endpoints on the hour and in very rapid succession. We ultimately landed on 1-second windows. The results were much better. We also noticed an interesting behavior from the clients. They would usually give up very quickly when we returned 429 responses, and as before, they would continue hammering the endpoint when we responded with 502s or 504s.
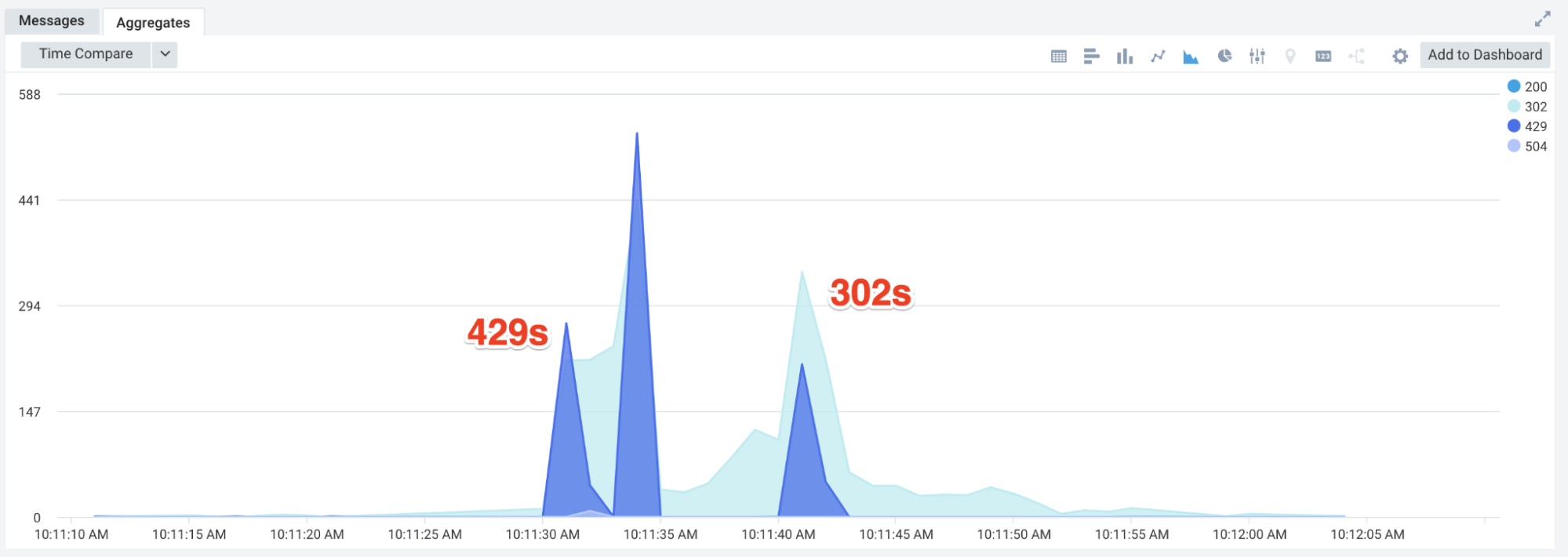
Lastly, while we don’t condone unauthorized pen tests or load tests, we occasionally have the curious adventurer try. They are often using tools like Burp or some script. Sometimes these are set up to scroll through endpoints or hit the same endpoint with different data. This rate limit implementation stops some of those, adding an extra security benefit.
The nice part of this rate-limiting implementation is that we can adjust the limits per route. On more sensitive or latent routes, we can be more aggressive with the limits. Often returning a 429 is enough to get the actor to slow down or back off entirely.
Example:
Let’s look at the following example. Say we want to rate limit user-agents that contain the word “fuzz” on our login page. We will use the sticky counter 0 with ‘track-sc0’ and track the IP with ‘src’. We use ‘table’ to tell the counter where to store the data. And lastly, we are using an anonymous ACL to check the user agent and path, you can also use a named ACL, but I’ve found the easiest readability to be inline. You can also have multiple ACLs like:
http-request track-sc0 src table table_login_limiter if { req.hdr(user-agent),lower -i -m sub fuzz } { url_beg /login }
This type of rule would only track IPs that came from a user-agent containing the string ‘fuzz’ and hitting our ‘/login’ page. The AND operator is implicit in ACLs. You might also wonder why I put the user-agent check in front of the ‘/login’ URL - this is because HAProxy short circuits ACL rules, so if the user-agent doesn’t contain ‘fuzz’ there is no need to evaluate the URL path. Having it the other way around would mean HAProxy would evaluate both rules for every request to the /login page. When you have hundreds of routing rules and more complex ACLs, this evaluation ordering is an important concept to understand for performance reasons.
Summary
HAProxy provides a lot of robust functionality out of the box. With limited overhead and configuration, we were able to cover our requirements laid out in the start of this blog - burst protection and thundering herd from clients and upstream resource protection, and security.